
You just onboarded a new client, opened their brief, and found a competitor list that feels half right and half outdated. A few names are obvious. A few are legacy players nobody worries about anymore. And the sites stealing visibility from them in search, local packs, directories, and AI-driven answers aren't on the list at all.
That's the problem with trying to find similar sites today. The task sounds simple, but the useful version isn't “show me websites like this one.” The useful version is “show me the businesses and publishers competing for the same demand, attention, and discovery surfaces.”
Agency teams usually learn this the hard way. A client says one company is their main rival, but keyword overlap points elsewhere. A backlink review shows another cluster of sites. Local search reveals businesses with weak websites but strong listing visibility. Then AI answers start citing sources the client never named in kickoff.
A good workflow fixes that. It starts rough and fast, gets stricter as evidence improves, and becomes automated once the pattern is stable.
Why Finding True Competitors Is Harder Than Ever
The first mistake new analysts make is trusting the client's definition of a competitor too strictly. Clients usually think in business-history terms. They name the company they pitch against, the brand they lost deals to last year, or the site they've watched for years. Search behavior doesn't care about that history.
A site can be a real competitor even if it sells a different package, targets a narrower location, or wins through informational content instead of product pages. Another site can look similar on paper and still be irrelevant if it serves a different audience segment.
The web is too large for manual comparison
The scale alone changes the job. A 2024 website statistics summary reports approximately 1.1 billion websites on the internet, with around 193.5 million active sites. It also notes that only about 18% of all websites are active. At that scale, nobody finds a reliable peer set by browsing around and trusting instinct.
Manual discovery still has value, but only as triage. Once the market is even moderately competitive, you need search patterns, categorization logic, and benchmarks to narrow the field into something usable.
Practical rule: if your competitor list came from memory, sales anecdotes, and a few branded searches, treat it as a draft, not a deliverable.
Similarity depends on what you are trying to compare
Many “similar site” tools frequently disappoint people. They return domains that are similar by one dimension, but the analyst expected similarity across every dimension at once.
In practice, there are several valid definitions:
- Search competitors are sites ranking for the same non-branded terms.
- Audience competitors attract the same visitors, even if their offerings differ.
- Local discovery competitors show up in Maps, directories, and review platforms.
- Commercial competitors compete for the same budget or buying intent.
- Citation competitors appear in AI-generated answers and source lists.
Those groups overlap, but they are not the same.
Agencies need an intelligence process, not a list
The useful output isn't a spreadsheet of “websites like ours.” The useful output is a tiered map: direct rivals, adjacent threats, aspirational benchmarks, and noise you can ignore.
That distinction matters because teams make different decisions from each group. Direct rivals shape content and landing page priorities. Adjacent threats reveal category expansion. Aspirational benchmarks help with UX, authority, and technical comparisons. Noise gets removed before it wastes reporting time.
When you approach the task this way, finding similar sites stops being a novelty lookup and becomes a competitive research system.
Quick Discovery with Search Operators and Free Tools
The fast pass matters because you often need directional context in the first half hour. You're not trying to be exhaustive yet. You're trying to avoid starting blind.

Start with search patterns, not tools
Open search and work from the client's actual market language. Use combinations like:
- Brand plus category terms such as the company name with product type, service type, or city.
- Service plus location searches to surface local operators the client may have missed.
- Topic plus modifiers like alternatives, best, top, compare, software, agency, near me, or pricing.
- site searches to inspect whether a domain has meaningful depth in a topic area.
The old related: operator can still be worth a quick check, but it's not something I'd build a process around. It can be sparse, inconsistent, and too opaque to explain confidently in client work. Treat it as a hint, not evidence.
A more dependable pattern is to search the client's highest-intent terms and write down the domains that appear repeatedly across organic results, paid results, local packs, directories, and editorial roundups.
Use free tool views for directional clustering
Once you have a seed domain, free versions of website intelligence tools can help you see its digital neighborhood. Simple browser checks then save time. You're looking for repeated domain associations, overlapping topic focus, and obvious category peers.
One useful primer for junior analysts is SearchTheTrend's competitor analysis, because it frames competitor discovery as a practical search workflow instead of a pure software exercise.
A simple quick-pass checklist looks like this:
- Search the brand and main services. Note recurring domains.
- Search top non-branded terms. Separate publishers from actual commercial competitors.
- Check local surfaces. Review Maps, directories, and review platforms.
- Open a free traffic or similarity view. Capture possible peers without overtrusting the numbers.
- Set lightweight monitoring. If the market changes often, basic alerting helps you spot new pages and mentions. A simple setup for managing Google Alerts is still useful for rough market watching.
A quick discovery pass should produce hypotheses. It should not produce confidence.
Know when the quick pass is enough
Sometimes the rough approach is sufficient. If you're auditing a small local market, a niche B2B service, or a short campaign with obvious rivals, manual discovery can get you close enough to act.
It breaks down when:
- The client spans multiple locations
- Publishers and competitors mix together
- Affiliate or review sites dominate the SERP
- The brand competes across local and national intent
- AI answers introduce citation sources that don't rank traditionally
That's the point where you stop collecting names and start building a defensible competitor map.
A Deep Dive Using Competitor Intelligence Platforms
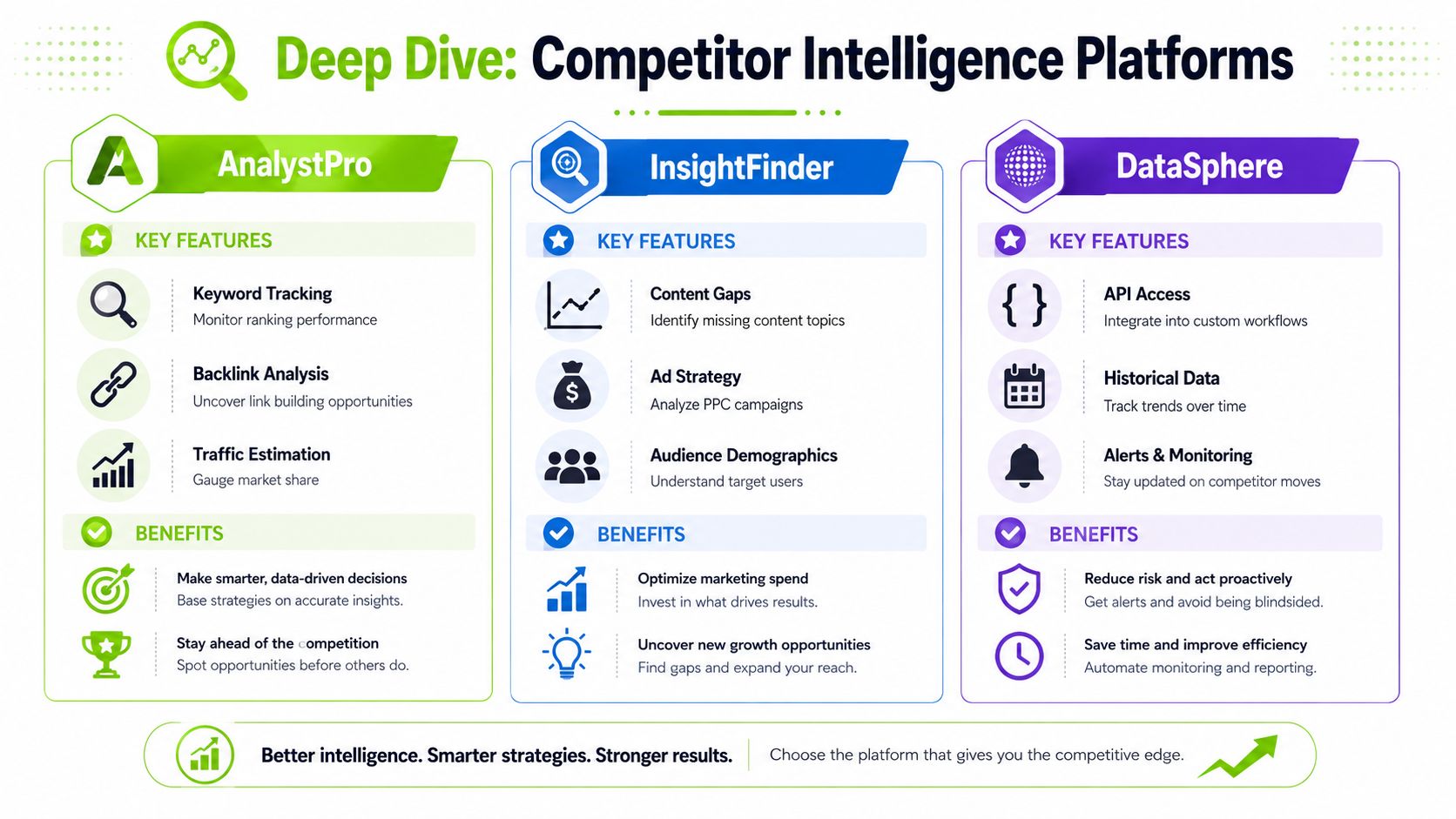
A client asks for a list of "sites like us," and the first tool returns forty domains. Half are publishers, a few are affiliates, and one is a marketplace that competes for attention but not for revenue. This stage is where analysts stop collecting names and start sorting by function.
Competitor intelligence platforms help because they expose different kinds of overlap. No single view is enough. I usually build three cuts first: search overlap, audience similarity, and authority proximity. If a domain shows up in all three, it deserves serious attention. If it appears in only one, it goes into a lower-confidence bucket until something else confirms it.
Use keyword overlap to find real search rivals
Start with non-branded keywords and segment them by intent. A domain that overlaps on "pricing," "services," "software," "near me," or comparison terms matters more than one that only overlaps on broad informational queries.
This method answers a specific question. Who is competing for the same demand before the user chooses a brand?
The pattern matters more than any single keyword. Repeated overlap across commercial clusters usually surfaces the competitors that affect pipeline, not just visibility. It also shows whether the rival wins with product pages, editorial content, location pages, or comparison assets. That distinction shapes the response plan. A product-led competitor calls for one playbook. A publisher absorbing evaluation-stage traffic calls for another.
Some teams use Surnex alongside Ahrefs or Semrush when they need platform-based visibility analysis that covers standard SEO datasets plus newer AI discovery surfaces. For a broader comparison of older traffic-estimation approaches versus newer options, see this breakdown of Compete web analytics alternatives.
Use similar-site tools as expansion tools, not decision tools
Similar-site databases are useful for widening the pool. They are weaker at qualification.
Similarweb's Similar Sites workflow is a good example. It can return up to 40 domains, ranked by an affinity score that estimates how close each site is to the one you entered. That is helpful for finding candidates you would not spot from the SERP alone, especially in broad categories or messy markets.
The trade-off is precision. Audience or traffic similarity can group together businesses with different monetization models, different geographies, or different conversion paths. I treat these outputs as prompts for review. They help analysts ask better questions. They should not decide the final competitor set by themselves.
A simple working model helps:
| Discovery angle | What it is good for | Where it goes wrong |
|---|---|---|
| Keyword overlap | Finding domains that compete for the same search demand | Brand-heavy sets can distort the list |
| Similar-site results | Expanding candidate discovery beyond obvious rivals | Domain-level similarity can hide business-model differences |
| Audience patterns | Spotting adjacent threats and substitution behavior | Shared visitors do not always mean shared offers |
Use backlink analysis to map authority clusters
Backlink analysis is less about raw link counts and more about market grouping. If several domains earn mentions from the same trade publications, association pages, "best of" lists, partner ecosystems, or niche directories, they are often being treated as part of the same category by the sites that curate the industry.
That helps in two ways. First, it finds competitors that keyword tools miss, especially in categories where referral and reputation matter as much as rankings. Second, it helps separate temporary SERP winners from established players with durable market recognition.
The questions I want answered here are practical:
- Which domains keep appearing in the same editorial lists or resource pages?
- Which sites share referring domains from category-relevant publications?
- Which adjacent competitors are already earning citations in the segment the client wants next?
Use traffic-source and audience views to catch indirect competitors
Some competitors do not mirror the client's site structure at all. They still intercept the same users through directories, referral deals, newsletters, social distribution, or strong branded demand. A keyword-only workflow misses that.
Traffic-source and audience reports are useful because they show acquisition strategy, not just ranking position. If one competitor depends on organic search and another gets a large share of demand from partnerships or direct traffic, the response should differ. The first is a search problem. The second may be a distribution problem.
Teams that operationalize this work across departments usually widen the scope beyond SEO. Competitive intelligence use cases give a practical view of how these signals feed monitoring, sales enablement, and market tracking.
Later in the review, I usually compare findings in one visual workspace:
The output from this stage should be tiered. Build one list of direct search competitors, one list of adjacent market players, and one watchlist for emerging domains or new entrants. That structure is easier to defend, easier to update, and far more useful than handing a client one flat spreadsheet of "similar sites."
How to Validate and Evaluate Your Competitor List
Most competitor lists fail at validation, not discovery. Teams collect names from tools, paste them into a deck, and move on. That's where bad benchmarking starts.
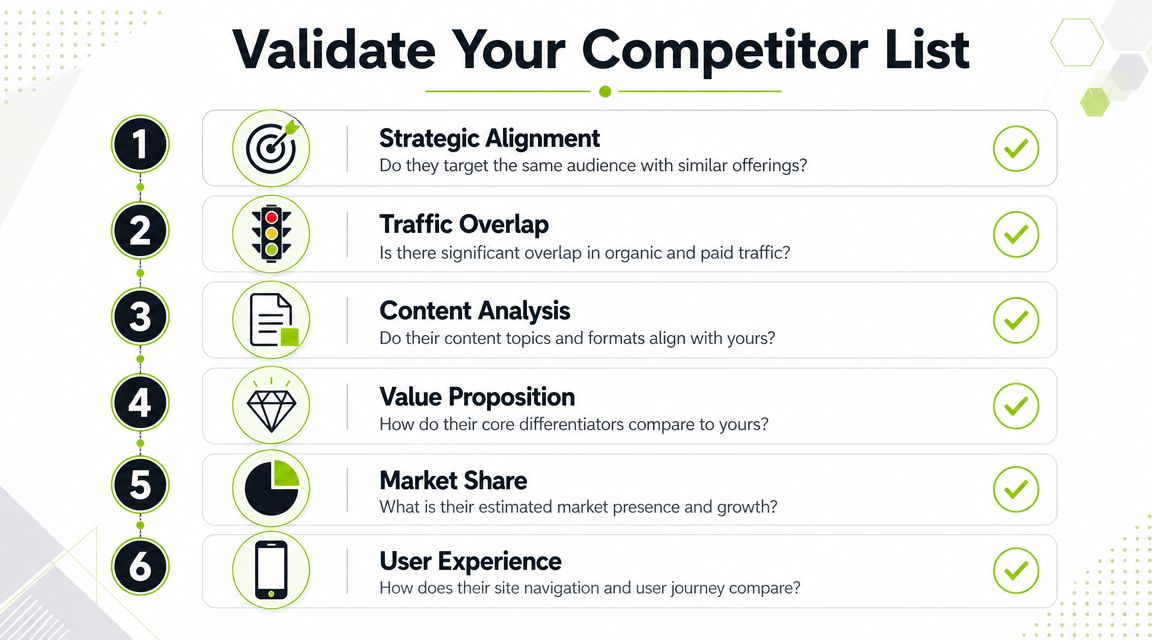
A site only belongs on the final list if it survives scrutiny from three angles: measurement quality, technical comparability, and strategic fit.
Treat third-party traffic numbers as directional
This is the first thing I tell new hires. Third-party traffic estimates can help you sort and compare, but they are not ground truth.
A peer-reviewed comparison of 86 websites found that Google Analytics reported 1,703.5 million total visits while SimilarWeb reported 1,060.1 million for the same sites. On average, SimilarWeb's estimates were 19.4% lower for total visits and 38.7% lower for unique visitors. That's enough variance to change how you interpret market position if you read the data too strictly.
So the rule is simple. Use estimated traffic to rank possibilities, not to declare precise market share.
If a competitor only looks comparable because of one traffic estimate, the comparison is weak.
Check whether the site is technically comparable
Two sites can compete for the same keywords while operating under very different technical constraints. One may be a lean CMS setup. Another may be a complex enterprise stack with heavy scripts, fragmented templates, or slower release cycles.
That difference matters because it changes what comparisons are fair. If your client asks why a competitor ships content faster or performs differently in Core Web Vitals-style checks, stack and implementation often explain more than topical overlap.
Tools that inspect frameworks, CMSs, analytics tags, hosting clues, and page performance help here. For competitor discovery work, I want to know whether the site is a valid implementation benchmark or just a topical benchmark.
Validate strategic intent, not just topical resemblance
A competitor list gets sharper when you ask commercial questions:
- Do they sell to the same customer type?
- Are they targeting the same geography?
- Is their conversion path similar?
- Do they win with product pages, lead gen, local listings, or editorial content?
- Would the client lose business to them?
That last question is the simplest and often the best. If the answer is no, keep the domain in a broader watchlist, not the core peer set.
Here's a framework I use during review:
| Signal | What It Reveals | Tools to Use |
|---|---|---|
| Keyword overlap | Whether the site competes in search demand | SEO platforms, rank trackers |
| Backlink neighborhood | Whether the market groups the domains together | Backlink analysis tools |
| Traffic-source mix | Whether they reach users through similar channels | Website intelligence platforms |
| Tech stack | Whether implementation comparisons are fair | Wappalyzer, BuiltWith, CRFT Lookup |
| Local presence | Whether they compete in maps and directory discovery | Google Maps, directories, review sites |
| Business model fit | Whether they are commercially comparable | Manual review, sales input, offer analysis |
For a more process-oriented walkthrough, this guide on how to find competitors of a website is useful because it separates raw discovery from validation logic.
Cut the list aggressively
A weak longlist creates bad reporting. Keep the final set small enough that each domain has a reason to be there.
I usually place domains into four buckets:
- Direct competitors with clear audience and offer overlap
- Search competitors that overlap in rankings but differ commercially
- Adjacent players that signal expansion or substitution risk
- Reference benchmarks that are useful for UX, content, or authority comparison only
That framing prevents one of the most common agency mistakes: comparing a local service business to a national publisher and calling both “competitors” with no qualifier.
Programmatic Discovery with APIs
Manual discovery works for one account. It gets messy when you manage many clients, multiple markets, or a category that changes every week.
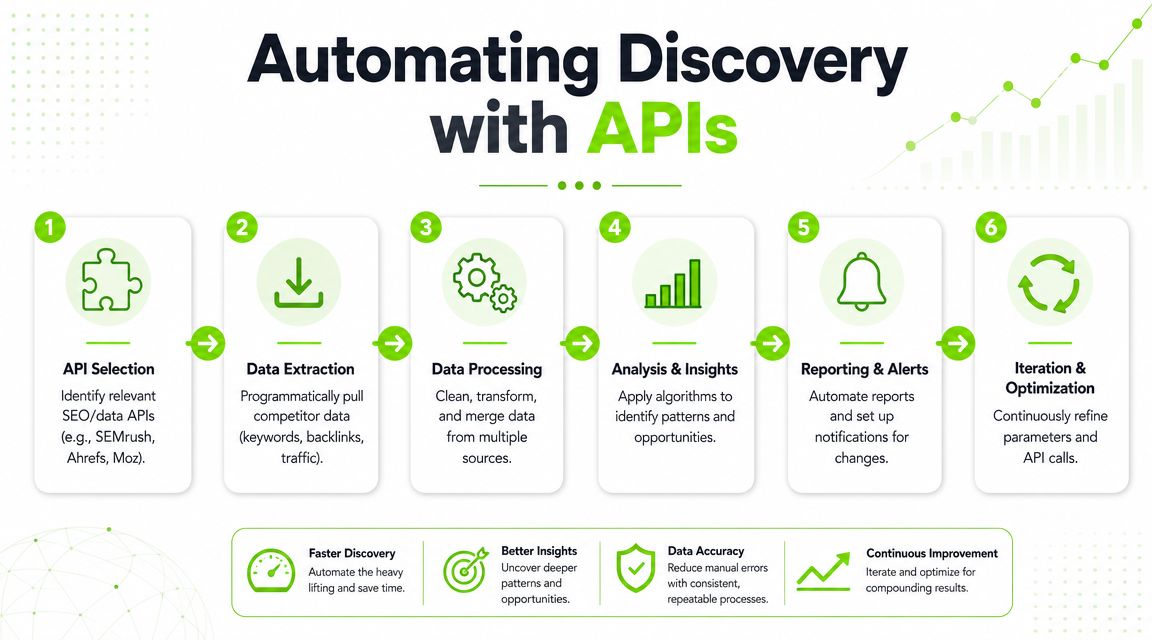
The scalable version of this job is programmatic. Instead of asking “who are the competitors today,” you build a system that keeps asking and flags change.
Build the pipeline around events
The cleanest API workflows start with triggers. Something changes, then the system checks for new or rising competitors.
Useful triggers include:
- Keyword movement when a new domain starts ranking across tracked terms
- Backlink acquisition when an unfamiliar domain appears in the same linking ecosystem
- Local listing changes when new entities appear in Maps or directories
- Citation monitoring when AI answers begin surfacing new domains
- Category page publication when a rival launches into a neighboring topic cluster
Each trigger should feed a candidate queue, not the final competitor table. Validation still happens downstream.
Pull from multiple surfaces, not just website indexes
One of the more overlooked realities in modern discovery is that competition doesn't start and end with websites. Guidance on finding businesses without websites highlights an underserved angle here: discovery now has to work across Google Search and Maps, directories, and AI answers, and most existing how-to content still treats the process as a manual lookup problem.
That matters because many local and service-based competitors have weak sites but strong discoverability through listings, reviews, and aggregator pages. If your pipeline only checks domains, you'll miss them.
A practical automated stack often includes:
- SEO platform APIs for rankings, backlinks, and domain comparisons
- Scraping or local data APIs for Maps and directory entity extraction
- Technographic lookups for stack validation
- Alerting systems that score candidates and push reviews to Slack, email, or your dashboard
Score candidates before a human reviews them
Automation helps most when it reduces junk. Give each candidate a simple scoring model based on evidence types.
For example, a domain gets higher priority if it appears in multiple keyword sets, shares referring domains, matches geography, and shows up across more than one discovery surface. A domain gets downgraded if it's only an informational publisher, a single-page directory mention, or an unrelated marketplace.
Automation should increase judgment, not replace it.
If you're designing this inside a reporting stack, SE Ranking API workflows are a useful reference point for how agencies can structure programmatic SEO data collection.
Keep the output operational
A good API workflow doesn't dump raw JSON into a warehouse and call it done. It creates actions.
Examples:
- Send an alert when a new domain enters a tracked keyword cluster
- Create a review task when a candidate meets your overlap threshold
- Refresh a competitor set when the same domain appears across multiple weeks
- Route local-only competitors to location-specific campaigns
- Update client dashboards with newly validated entities
That's the difference between automated discovery and automated clutter.
Building a Continuous Competitor Monitoring System
A competitor list goes stale faster than typically expected. You build it during onboarding, approve it in a strategy deck, and six weeks later a new aggregator, local player, or AI-cited publisher starts taking visibility from the client.
That is why I treat competitor discovery as an operating system, not a one-time research task. The goal is simple. Keep a current list of domains and entities that can affect traffic, conversions, local visibility, or citation share across search interfaces.
What the ongoing system should watch
A good monitoring setup tracks more than rank changes. It also checks whether a domain is becoming a meaningful competitor for the same reason your client wins business.
A website intelligence approach using tools like CRFT Lookup or Wappalyzer adds a useful layer here. It helps confirm whether newly surfaced sites are built on a comparable stack, publish at a similar pace, or have technical traits that can explain sudden visibility gains. That saves time during review. A site that overlaps on a few terms but runs on a completely different model often belongs on a watchlist, not in the core competitor set.
I usually keep monitoring tied to four practical questions:
- Which new domains are showing up in the client's priority topics?
- Which adjacent sites are starting to overlap with commercial or local-intent queries?
- Which entities are gaining visibility in maps, citations, or AI answers without a strong traditional site?
- Which site or content changes could explain movement in search visibility?
Watch market edges, not just established rivals
The biggest misses usually come from the edge of the category. An old competitor is easy to track. A fast-growing niche site, franchise location network, or programmatic publisher is harder to catch early, and those are often the ones that change the search mix first.
I also like to monitor domain activity around the category itself. For teams looking to spot expansion plays, rebrands, or acquisition targets, this guide on how to find high-value domains fits well beside competitor monitoring.
The point is not to collect more domains. The point is to spot meaningful movement before it shows up in a quarterly review.
Teams that do this well keep one repeatable workflow. They discover candidates, validate them, score their relevance, and review changes on a fixed cadence. This is important because the competitor set differs between traditional search and AI interfaces.
If your team needs one workspace for that process, Surnex gives agencies and in-house teams a place to track traditional SEO signals alongside AI visibility, compare competitors across modern search surfaces, and send the data into custom workflows through its API.


