
A client sends over a screenshot from Google AI Overviews. Their competitor is cited in the answer. Your client is missing, even though they still rank well in the organic results. That is the reporting gap AI visibility tools now have to close.
For agencies and in-house teams, rankings alone no longer explain what buyers see. Product comparisons, summaries, recommendations, and citations now happen inside ChatGPT, Google AI Overviews, Perplexity, Claude, Gemini, Copilot, Meta AI, Grok, and DeepSeek. If your reporting stack cannot show where a brand appears, why it was cited, and which sources shaped the answer, strategy gets delayed until after the visibility loss has already happened.
That changes what “LLM optimization” means for this category. In an AI visibility tool, optimization is not just about making a model faster or cheaper to run. It is about building a system that can detect answer-level presence, trace citations back to evidence, and give account teams something they can act on during the current reporting cycle.
The priority order matters. Some methods improve trust in the output. Others reduce latency or cost. Others make cross-engine monitoring practical at scale. For teams doing generative engine optimization, the operational goal is straightforward: measure brand presence inside AI answers, explain gaps, and turn those findings into content, digital PR, and technical SEO actions. If you want the broader search context behind that shift, this guide to generative engine optimization is a useful starting point.
The eight strategies below are ranked for that job. They focus on what helps AI visibility platforms produce grounded monitoring, useful diagnostics, and faster recommendations for agency workflows. Retrieval comes first for a reason. It has the biggest impact on whether the model is reporting from current evidence or polished guesswork. For a good primer on how RAG enhances LLMs, it helps to start with the retrieval layer before looking at prompt design, model tuning, or caching.
1. Retrieval-Augmented Generation
RAG is the first optimization I'd prioritize for any AI visibility product because it fixes the most common failure mode in LLM reporting. A model without retrieval will sound confident while blending stale rankings, old citations, and generic SEO advice into one neat paragraph. That's dangerous when an account manager is turning that output into client recommendations.
An AI visibility tool needs the model to pull live or near-live information before generating its answer. That means current brand mentions, tracked prompts, cited URLs, backlink context, audit issues, and competitor comparisons. If the tool can retrieve the right evidence first, the model has a chance to produce something grounded instead of polished nonsense.
Here's the visual version of that workflow:
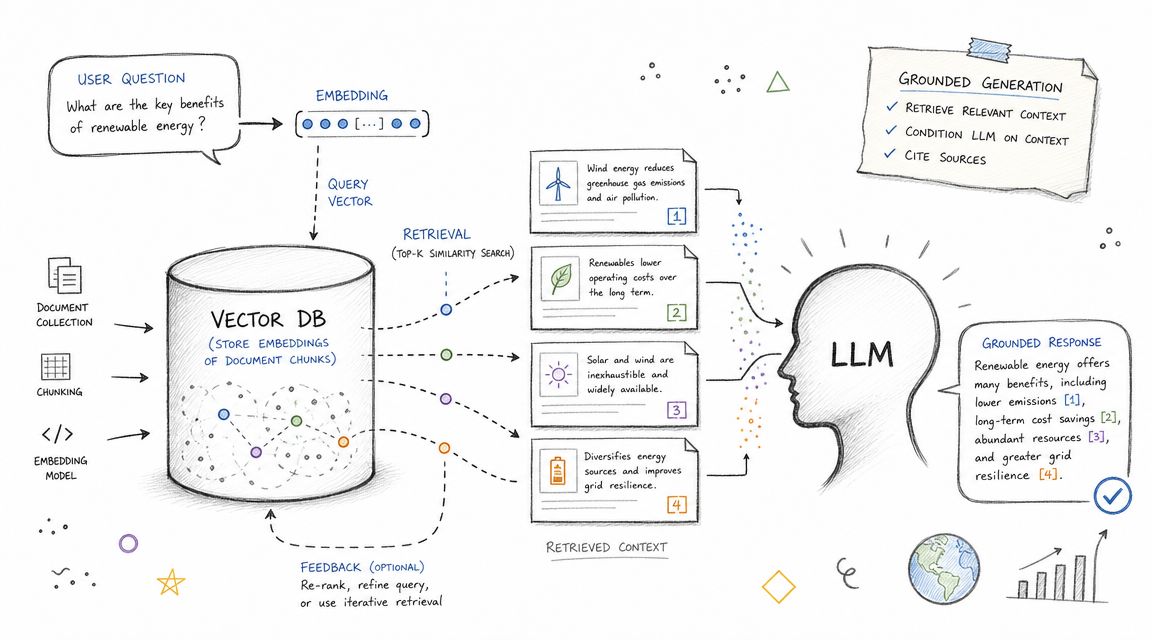
What good RAG looks like in practice
Perplexity is a familiar public example because users can see the grounding behavior through citations in the answer flow. In agency software, the same principle matters even more. If a strategist asks why a competitor is appearing in AI answers for a commercial query, the system should retrieve tracked evidence first, then explain the likely drivers.
A practical setup usually works best with hybrid retrieval. Semantic search helps match messy natural-language questions, while keyword retrieval still matters for exact entities, branded phrases, product names, and URL-level reporting. Teams building AI search workflows often frame this under generative engine optimization, but the underlying requirement is simple. The model has to see the right evidence before it speaks.
Practical rule: If your AI visibility assistant can't show where its answer came from, treat the answer as a draft, not a deliverable.
Where agencies usually get it wrong
The biggest mistake is dumping raw SEO data into a vector database and expecting magic. Data needs structure. Rankings, citations, crawl diagnostics, content inventories, and competitor snapshots should be chunked in ways that match real agency questions.
A better pattern looks like this:
- Group by decision type: Store chunks around tasks like citation gap analysis, brand comparison, or AI Overview appearance review.
- Keep entities explicit: Preserve brand names, product lines, locations, and cited page URLs so retrieval doesn't blur important distinctions.
- Use fallback retrieval: If semantic search misses, fall back to exact-match data for branded prompts, titles, and known URLs.
If you want a simple outside explanation of why this works, this overview of how RAG enhances LLMs is useful. In an AI visibility platform, RAG isn't a nice add-on. It's the layer that turns model output into something an agency can defend.
2. Prompt Optimization and Chain-of-Thought Engineering
Prompting is where many teams waste time because they treat it like copywriting instead of interface design. In AI visibility tools, prompts determine whether the model gives a vague narrative or a useful diagnostic. The difference usually comes down to structure.
A weak prompt asks, “Why is our client not showing up in AI Overviews?” A strong prompt defines the brand, competitor set, engine, query type, citation evidence, recency requirement, and output format. That doesn't make the model smarter. It makes the task narrower and more testable.
Build prompt libraries around actual agency work
I've seen the best results when teams stop improvising and create prompt templates for recurring requests. Account managers, SEO specialists, and executives don't ask the same questions, so they shouldn't use the same prompts either.
Useful prompt families include:
- Competitive diagnosis: “Compare our brand and two competitors for this prompt cluster. Identify citation differences and missing evidence.”
- Executive summary: “Summarize visibility movement in plain English, with causes separated from assumptions.”
- Content actioning: “List pages most likely to support better inclusion based on current citation patterns and content coverage.”
This is also where semantic context matters. Prompt templates that understand related terms, entities, and topic relationships tend to perform better than templates built around exact phrases alone. That's one reason teams still benefit from understanding concepts behind latent semantic indexing in SEO, even if modern retrieval and embeddings have moved beyond the old terminology.
What works better than “be more specific”
Prompt optimization is not about stuffing instructions into a wall of text. It's about sequencing. Give the model context, then constraints, then the job, then the output format.
Ask the model to separate observed evidence from interpretation. That one instruction improves reporting quality more than most teams expect.
Few-shot examples help too, especially when your platform supports multiple LLM backends. If one example shows the model how to explain a citation gap without overclaiming, you'll get more consistent outputs across engines. For teams that need a broader primer, this guide on prompt engineering for AI workflows is a reasonable starting point.
What doesn't work is blindly asking for chain-of-thought and dumping every internal reasoning step into user-facing output. For client work, the better move is hidden reasoning with visible conclusions, evidence, and uncertainty labels. Agencies need answers they can present, not notebooks full of model self-talk.
3. Model Optimization Quantization, Distillation, and Fine-Tuning
An agency dashboard can feel fine at ten client queries a day and break at scale. Once teams start tracking brand mentions across answer engines, prompt sets, competitors, and reporting windows, model cost and latency start shaping product quality as much as feature depth.
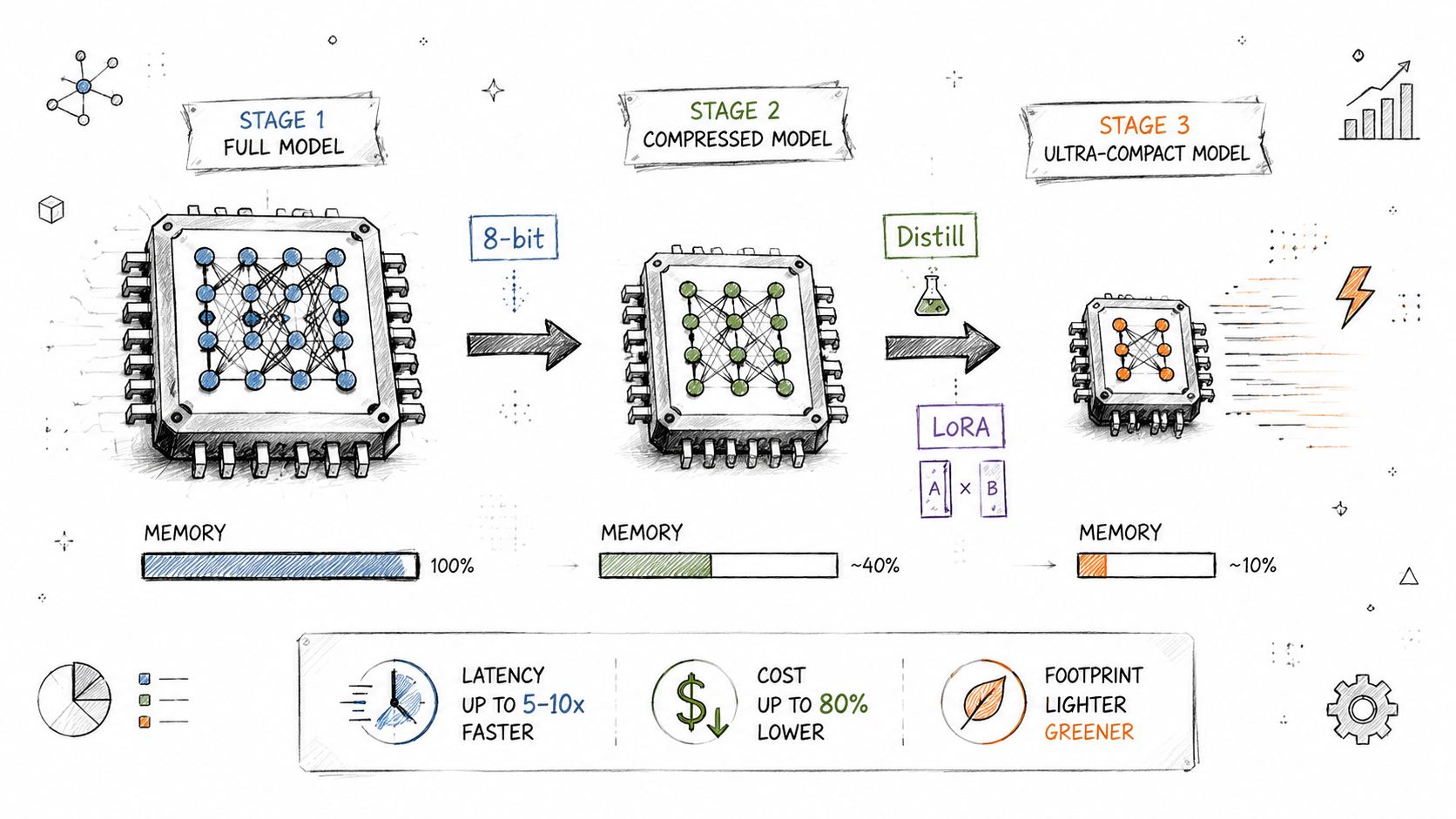
For AI visibility tools, this section is about triage. Use the full model where judgment matters. Use smaller adapted models where the job is repetitive, bounded, and easy to verify. That usually means a compact model can handle first-pass classification, entity cleanup, citation labeling, and summary drafting, while a larger model steps in for ambiguous comparisons or client-facing explanations.
Where each technique fits
Quantization cuts memory use and serving cost. Distillation transfers useful behavior into a smaller model. Fine-tuning, including parameter-efficient methods, teaches the model the language and edge cases your analysts deal with.
That domain language is narrow in a useful way. A model built for AI visibility should recognize prompt clusters, citation gaps, entity ambiguity, competitor overlap, and the difference between strong organic rankings and weak presence in answer engines. Teams building workflows around LLM brand visibility need that precision because generic chatbot behavior tends to blur those distinctions.
I usually treat these three methods as a priority stack, not a menu:
- Quantize first when inference cost is the problem and output quality is already acceptable.
- Distill next when you need lower latency for common tasks such as labeling, routing, or structured summarization.
- Fine-tune last when the model consistently misses domain-specific judgments that affect reporting quality.
Good trade-offs for production teams
The main trade-off is simple. More compression gets faster responses and lower cost. It can also reduce accuracy on the exact tasks agencies care about most, especially brand disambiguation, weak citation detection, and cross-engine comparison.
A safer rollout looks like this:
- Start with moderate quantization: Test whether lower precision changes citation interpretation, source selection, or explanation quality.
- Fine-tune on real workflow data: Support tickets, analyst QA notes, report comments, and client questions usually teach the model more than generic instruction sets.
- Benchmark on failure cases: Include competitor confusion, stale-source handling, branded query overlap, and prompts with incomplete context.
- Protect freshness rules: Smaller models fail faster when they summarize outdated material. Techniques similar to conditional content validation behind 304 Not Modified workflows help reduce waste without serving old conclusions.
This matters for margin and trust. Agencies need a stack that stays fast during reporting spikes, but they also need outputs account teams can defend in front of clients. In practice, the best setup is rarely the most compressed model. It is the cheapest model that still preserves judgment on the visibility metrics your team sells.
4. Semantic Caching and Response Memoization
A lot of agency questions repeat. They just arrive in slightly different wording. “Show visibility changes for last month,” “what changed in the past few weeks,” and “give me a recent AI visibility update” are often asking for the same underlying response pattern. If your platform regenerates each answer from scratch, you're paying for redundancy.
Semantic caching fixes that. Instead of matching exact text only, the system recognizes that similar requests can reuse prior answers or partially reuse their building blocks. That reduces latency and cost, and it makes the product feel more stable during heavy reporting cycles.
The cache should mirror reporting behavior
The simplest useful design is a tiered system. Exact-match cache first. Semantic similarity cache second. Full retrieval and generation only when the request is new or the underlying data has changed.
For AI visibility tools, this works especially well with repeated client workflows:
- Routine summaries: Weekly and monthly rollups often follow the same structure.
- Competitor comparisons: Many are reruns with a new prompt set or updated date range.
- Executive briefings: Leadership asks the same high-level questions every cycle.
A lot of teams overlook freshness rules. That's where caching can backfire. Rankings, citations, and engine behavior don't all change at the same speed, so one expiration window for everything is sloppy engineering. Strong cache invalidation works the same way efficient technical SEO does, which is why the logic behind 304 Not Modified handling is a helpful mental model even outside crawling.
What not to cache too aggressively
Don't cache anything that users assume is live unless your interface makes freshness obvious. If a strategist thinks they're looking at current AI Overview appearance and they're really seeing an older synthesized answer, trust drops fast.
Cached language is fine. Cached assumptions are not.
The best implementations cache intermediate work too. Retrieved evidence sets, prompt templates, and partial summaries can all be memoized. That way you're not only speeding up the final response. You're reducing repeated work throughout the stack. For agencies serving multiple accounts, that's one of the easiest wins available.
5. Mixture of Experts Architecture
One model trying to do everything usually turns into average performance everywhere. AI visibility is too fragmented for that now. Different engines surface different answer styles, citation patterns, and retrieval quirks. A platform that monitors ChatGPT, Google AI Overviews, Perplexity, Claude, Gemini, Copilot, Meta AI, Grok, and DeepSeek is dealing with many surfaces, not one unified environment, as noted in Zapier's roundup of AI visibility tools.
That's why mixture of experts makes sense. Instead of one generalist path for every query, you route requests to specialized experts. One can focus on Google AI Overview-style summarization behavior. Another can focus on conversational product discovery in ChatGPT. Another can handle cross-platform competitor benchmarking.
Specialization beats one-size-fits-all reporting
This architecture matters most when a user asks for blended analysis. An in-house SEO lead might ask why the brand appears in one engine but not another. A general model tends to smooth over those differences. Expert routing preserves them.
A practical expert map for agency software might include:
- Engine expert: Handles surface-specific interpretation and output patterns.
- Content expert: Reviews page structure, answer formatting, and likely citation support.
- Competitive expert: Compares entities, cited domains, and overlap between brands.
- Executive summarizer: Converts technical findings into clear account-level narrative.
The real trade-off
MoE isn't free. Routing mistakes create weird outputs. If the system sends a technical crawl issue to the wrong expert, you get polished but irrelevant analysis. That's why teams need evaluation sets that mirror real tickets, not just demo prompts.
What works is tight specialization with feedback loops. Review expert usage, spot overloaded paths, and retrain the router when it keeps choosing the wrong analytical lens. What doesn't work is building many experts because the diagram looks impressive. If each expert doesn't own a clear job, the architecture becomes expensive theater.
6. Real-Time Data Integration and Streaming
AI visibility changes fast enough that batch-only reporting gets old before the meeting starts. If a competitor suddenly gains citations across a prompt cluster, or if a brand disappears from a previously strong answer surface, teams need more than a weekly snapshot. They need current context and alerting.
Real-time integration matters because LLMs can't invent freshness. They can only use the inputs they receive. If your platform updates too slowly, the model will produce coherent explanations based on stale conditions.
Stream changes, not the whole universe
The strongest systems don't keep stuffing full datasets into the context window. They detect events, summarize what changed, and stream only the relevant deltas into downstream analysis. That keeps costs and context clutter under control.
Common event types include:
- Citation appearance changes: A tracked page enters or exits an answer surface.
- Competitor movement: Another brand starts appearing across a prompt group where your client was weak.
- Technical blockers: Crawling, indexing, rendering, or structured data issues show up alongside visibility drops.
Better agency workflows come from event design
A useful streaming layer supports different audiences. Analysts might want detailed event logs. Account leads need digestible summaries. Executives need a short explanation with clear action.
The mistake is treating “real-time” as a product label instead of a workflow. If alerts fire constantly, people mute them. If events aren't grouped by business importance, no one knows what to do first. The best implementation usually starts with a smaller set of meaningful alerts, then expands once the team trusts the signal.
For agencies, that discipline matters more than speed alone. A slightly slower alert that's accurate and actionable beats a constant stream of noise every time.
7. Explainability and Attribution Frameworks
If your tool says a brand's visibility improved, the next question is immediate. Why? If it can't answer that clearly, the platform becomes hard to trust, especially in client-facing work.
Explainability is not an academic feature here. It's the difference between a defensible recommendation and a black-box opinion. Agencies need to show what changed, which evidence supports the claim, and where uncertainty still exists.
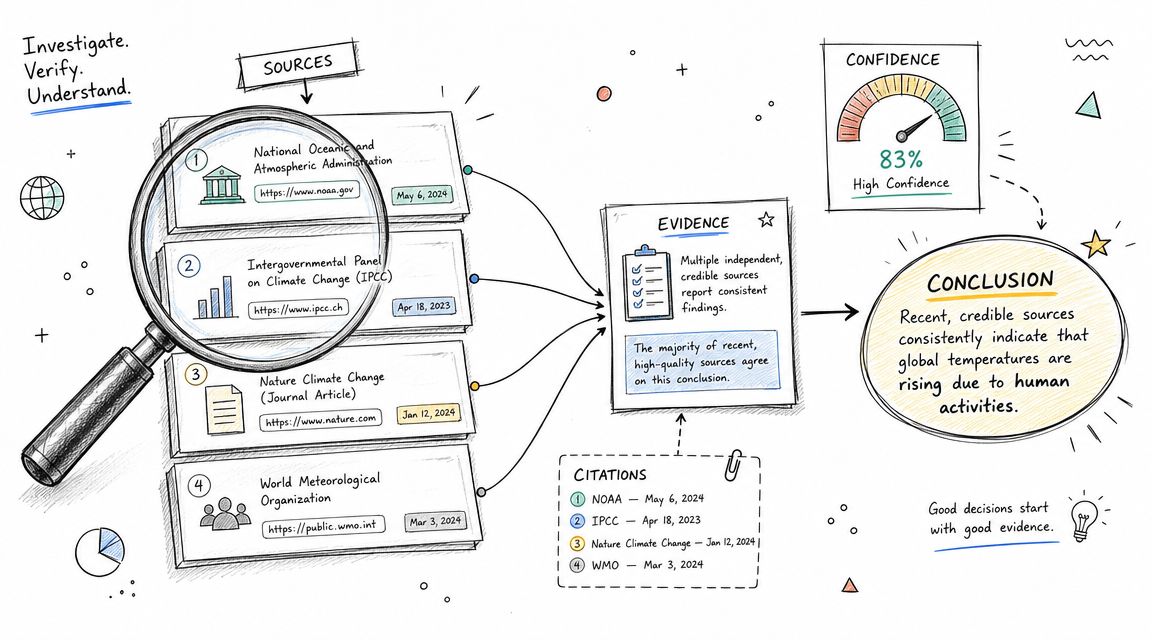
Evidence should travel with the insight
A good attribution framework attaches proof directly to every major statement. If the system says a competitor is cited more often for a topic cluster, it should point to the tracked prompts, cited URLs, surfaces involved, and date range used. If it says content freshness may be a factor, it should distinguish that from confirmed evidence.
I like “evidence cards” for this. Each card can show the claim, the supporting inputs, and the confidence level. That format works for internal analysts and for client reporting because it forces discipline on the model output.
The safest AI-generated insight is the one a strategist can independently verify in under a minute.
What agencies should insist on
The minimum standard is source tagging and auditability. Every recommendation should be traceable. Every summary should separate observation from interpretation. Confidence labels should reflect data quality and recency, not just model confidence theater.
Counterfactual forecasting is where teams often overreach. It's tempting to say, “If we improve this factor, visibility will rise by a specific amount.” Unless you have very strong causal modeling, don't do that. Explain likely direction and rationale qualitatively instead. In this category, honest uncertainty is more persuasive than fake precision.
8. Multi-Modal Integration and Cross-Platform Embeddings
Text-only analysis misses too much now. Brands show up through product images, video stills, review formatting, comparison tables, organization details, and structured page elements that influence how AI systems interpret them. If your visibility tool only embeds plain text, it's leaving useful signal behind.
Multi-modal integration helps the platform connect those signals. It can compare page copy with supporting visuals, relate structured metadata to cited content, and build a more complete picture of why one asset travels across AI surfaces and another doesn't.
Visibility has more than one shape
This matters most for brands with complex content ecosystems. E-commerce teams need product information, reviews, and imagery understood together. SaaS teams need documentation, landing pages, screenshots, and third-party mentions connected within the same analytical layer.
Cross-platform embeddings also help when the same brand is represented differently depending on the engine. One surface may reward concise explainer content. Another may rely more heavily on cited reviews or product-style summaries. Unified embeddings make those mismatches easier to detect.
A practical use case looks like this:
- Build content fingerprints: Represent a brand's pages, assets, and metadata in one embedding framework.
- Compare cited and uncited assets: Identify what the winning pages have in common across engines.
- Find reusable support material: Match underperforming pages with adjacent assets that could strengthen entity clarity or answer readiness.
Why this is often a later-stage move
This isn't where I'd tell most agencies to start. If retrieval, prompting, and attribution are weak, multi-modal sophistication won't save the product. But once the foundation is stable, cross-platform embeddings can become a serious advantage because they connect SEO, content, and AI visibility work inside one analytical model.
For teams managing lots of client assets, that unified view is what turns scattered observations into a strategic system.
Top 8 LLM Optimization Strategies for AI Visibility Tools
| Approach | 🔄 Implementation Complexity | ⚡ Resource & Performance Requirements | ⭐ Expected Outcomes | 📊 Ideal Use Cases | 💡 Key Advantages / Tips |
|---|---|---|---|---|---|
| Retrieval-Augmented Generation (RAG) | High, adds retrieval pipeline, indexing, and maintenance | Moderate–High, vector DBs, retrieval compute; adds latency unless optimized | High, grounded, up-to-date, citation-backed responses | Time-sensitive ranking/visibility reports and citation-tracked client reporting | Structure SEO data as embeddings; use hybrid retrieval; monitor retrieval latency |
| Prompt Optimization & Chain-of-Thought | Low–Medium, no infra change but requires expert design & iteration | Low, minimal compute; mainly human engineering effort | Medium–High, better reasoning and explainability without retraining | Complex diagnostic queries, explainable client insights, rapid prototyping | Build prompt libraries, few-shot examples, A/B test prompts, include guardrails |
| Model Optimization (Quantization/Distillation/LoRA) | High, model compression and fine-tuning expertise needed | High upfront compute for tuning; lower inference costs and faster runtime | High, much faster inference and lower cost; risk of some quality loss | Real-time dashboards, edge deployment, large-scale API cost reduction | Start with 8-bit quantization; benchmark; use LoRA and gradual rollouts |
| Semantic Caching & Memoization | Medium, caching layer + semantic matching logic | Moderate, storage for embeddings, cache infra; large savings on API calls | High, large reduction in redundant calls, much lower latency for cached queries | High-volume, repetitive visibility queries and real-time dashboards | Use tiered cache (exact → semantic → regenerate); tune TTL and similarity thresholds |
| Mixture of Experts (MoE) Architecture | Very High, complex routing, training and orchestration | Very High, many expert models, routing overhead; sparse activation mitigates load | High, specialized accuracy per domain with efficient sparse compute | Diverse platform specialization (Google AI Overviews, ChatGPT, niche verticals) | Deploy experts per platform, monitor utilization, use auxiliary losses to stabilize routing |
| Real-Time Data Integration & Streaming | High, streaming pipelines, stateful context management | High, continuous ingest, storage, and processing; potential API costs | High, truly current insights and instant alerts | Agencies requiring live alerts, immediate competitive intelligence, anomaly detection | Start with hourly feeds; use change-detection thresholds and differential updates |
| Explainability & Attribution Frameworks | Medium, add attribution, confidence scoring, audit trails | Moderate, extra compute to generate explanations and evidence cards | High, improves trust, compliance, and debuggability | Client reporting, regulated industries, internal QA and audit workflows | Tag sources for every claim, present evidence cards and confidence scores, test with non‑technical users |
| Multi-Modal Integration & Cross-Platform Embeddings | Very High, multi-modal training, adapters per platform | Very High, large datasets and compute to embed diverse modalities | High, holistic visibility across text/image/voice; richer insights | Cross-format brand visibility, image/voice-aware platforms, content repurposing | Create platform-specific embedding adapters, use contrastive learning and temporal embeddings |
From Tracking to Strategy Your Next Move in AI Visibility
The best LLM optimization options for AI visibility tools are not interchangeable. Some improve factual grounding. Some improve speed. Some reduce operating cost. Some make outputs explainable enough for a client call. The important point is that they compound when you implement them in the right order.
If I were prioritizing this roadmap for an agency or in-house team, I'd start with retrieval-augmented generation and prompt optimization first. Those two choices have the fastest impact on answer quality because they control what the model sees and how it is asked to respond. In practice, they reduce the most painful problems early. Hallucinated explanations, vague summaries, and recommendations that sound smart but aren't tied to evidence.
Next, I'd tighten the economics of the system. Model optimization and semantic caching usually deliver the biggest operational gains once usage grows across clients, regions, and prompt sets. They help teams keep performance stable without turning every dashboard query into an expensive generation event. For agencies, that margin protection matters just as much as raw product quality.
After that, I'd invest in architecture that supports scale and trust. Mixture of experts helps preserve nuance across fragmented answer engines. Streaming data helps teams react to actual changes instead of stale snapshots. Explainability frameworks make the insights usable in reporting, planning, and stakeholder reviews. Multi-modal integration then becomes a smart expansion, especially for brands where images, reviews, product data, and structured content all influence how AI systems represent them.
This shift in search also changes how you should evaluate vendors. Broad engine coverage matters because the market has moved from single-engine monitoring to multi-engine visibility, with leading tools tracking a growing set of surfaces rather than only ChatGPT, according to this overview of AI visibility platform coverage. Large behavioral datasets can matter too. For example, Profound's Conversation Explorer is described as analyzing more than 400M real user prompts, which shows how some platforms are moving beyond simple rank-style tracking toward prompt-level intelligence.
That said, software still needs to fit your workflow. A platform can have wide coverage and still create a monitoring tax if your team has to manually turn every chart into action. The practical goal is to move from observation to decision, then from decision to execution.
If you need a starting point, establish a baseline in a unified platform and pressure-test it against real client questions. Surnex is one relevant option for teams that want AI visibility and core SEO signals in the same working environment. Once you can trust the baseline, layer the optimization methods above in order of business impact, not novelty. That's how AI visibility tooling becomes a strategic service instead of another dashboard.
If you're trying to turn AI visibility tracking into something clients and stakeholders can use, take a look at Surnex. It brings AI search visibility together with rankings, backlinks, audits, and content opportunity workflows so agencies and in-house teams can monitor where brands appear, spot citation gaps, and act from one place instead of stitching together separate tools.


